
Server maintenance in the Exalogic Virtual Datacenter (part 2)
Published on: Author: Jos Nijhoff Category: OracleIn the previous post I started testing with rolling maintenance options using the information provided in My Oracle Support note 1551724.1, titled “Making an OVS Node Unavailable for vServer Placement in Exalogic Virtual Environments using EMOC.”
I described how nodes can be “tagged” so they will not accept new vServers, even in the case where vServers are automatically restarted because they are in HA mode. I also discussed how this new information can be used to relocate vServers to other nodes, effectively performing vServer migration (indirectly).
In this second post I will demonstrate how this would work in a real life scenario, with some clustered Oracle environments (Traffic Director, Oracle Service Bus 11g) and some non-clustered stuff (Cloud Control, PeopleSoft Campus Solutions, Traffic Director admin server, Fusion HCM demo node) hosted on our Exalogic X2-2 system. A home-grown Qualogy application was also thrown into the mix. The clustered environments are spread over nodes 6 and 8 respectively. For our test, primary nodes of each HA configuration are running on node 6 and secondary nodes on node8 as shown below:
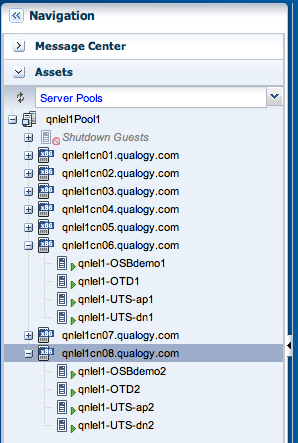
The non clustered applications run on node 7 :
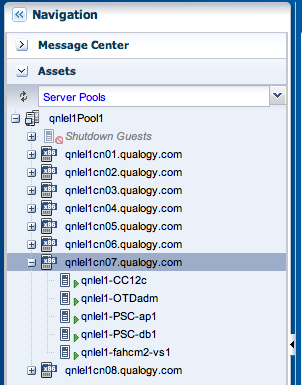
Nodes 7 and 8 have been tagged with vserver_placement.ignore_node=true and have been put into maintenance mode. We are now ready to stop and restart all vServers on nodes 7 and 8 in order to relocate them elsewhere. Subsequently we can halt these compute nodes so they can be serviced. In our case, preventive replacement of the RAID HBA batteries for the SSD’s (see the previous post here).
We now start testing our procedure by taking all the secondary cluster nodes offline. We neatly stop the application/middleware instances running in these vServers first, checking that their functions remain available for users via their primary node counterparts running on node 6. Then we can also stop the vServers they were running on. In the below example, we stop vServer “qnlel1-UTS-dn2” first.
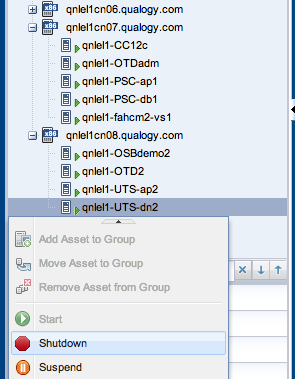
Thus, we work our way up the list until all vServers running on node 8 have been stopped. Next, we go to the respective project folders (account folders) in the Vitual Datacenter cloud folder to restart them. Below, this is shown for the vServer “qnlel1-UTS-dn2” in the “QEL-MediationUTS-project” that we stopped first.
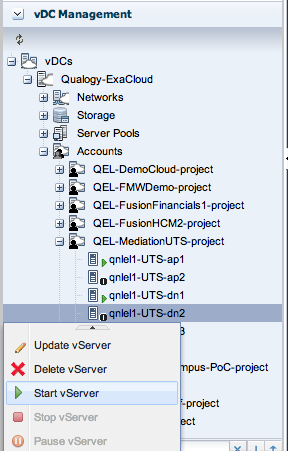
After confirming, we see the vServer is restarted. Next we also restart our secondary OSB server “qnlel1-OSBdemo2” and the other vServers we just stopped.
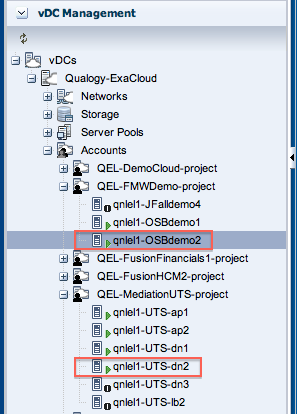
At the basic “Cloud User” level, in the vDC Management section we cannot see where the vServer is started (on which compute node), only that it is up & running again, which is all I need to know as a project member. However, because I have more admin roles assigned to my account (such as Cloud Admin and Machine admin) I can also access the “Assets” section. See this blogpost for more details on roles and permissions in the Exalogic Virtual Datacenter.
Under “Server Pools” in the Assets section we check where our newly restarted vServers have been allocated.
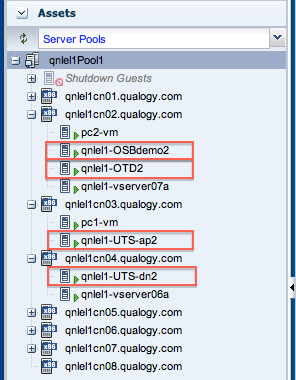
Thus, we find that they have now been redistributed among compute nodes 2, 3 and 4, effectively performing an offline vServer migration.
Next we also stop our non-clustered application/middleware instances so we can shutdown and reallocate the vServers running on compute node 7. On these vServers, I have enabled vServer High Availability mode for each of them (see my previous post). This means that I will not have to restart these vServer myself if I employ a shutdown method that triggers the automatic recovery function, such as a halt command at the OS level.
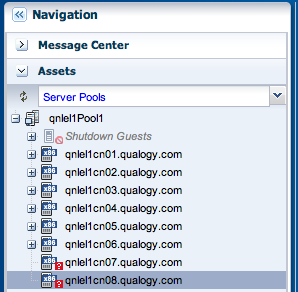
Indeed, after halting my vServers at the Linux prompt and waiting a little, I find that nodes 7 and 8 are now vacant as I cannot expand their icons (in purple below) and my vServers (marked in red) have been restarted on compute nodes 2, 4 and 5.
Once our relocated vServers are back online, we can restart the application/middleware instances on them, restoring their services and redundancy.
Now our compute nodes 7 and 8 themselves are ready to be taken offline for maintenance, either by giving the halt command at the OS level or by issuing a graceful shutdown and poweroff via their remote management web-interfaces (ILOM).
After shutting them down, the two compute nodes are marked as unavailable in both the Exalogic Control dashboard and in Oracle VM Manager, as demonstrated below.
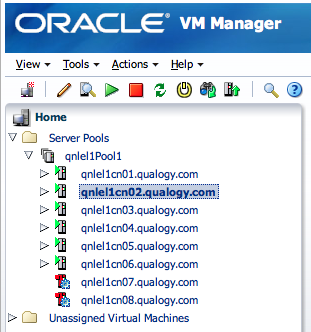
After letting the Oracle engineer perform the HBA battery replacements and restarting our two compute nodes (power on), they can be taken back into service once they are up & running again. This is done by a) taking them out of maintenance mode and b) “untagging” them, either by setting vserver_placement.ignore_node to false or by removing this tag altogether :
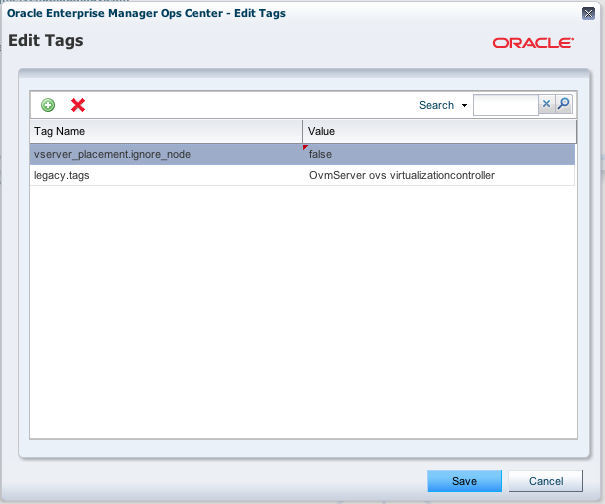
Here I have opted to set the tag to false instead of deleting it.
Thus, we have performed our rolling maintenance for nodes 7 and 8, and we can complete our maintenance task by repeating this procedure for nodes 5 and 6, then 3 and 4, etc. or another appropriate combination of nodes, as long as we do not interrupt services by taking out all nodes in a middleware or application cluster at the same time. You get the gist of it.
Conclusion
With this exercise, I have demonstrated that you can perform hardware or software maintenance on Exalogic compute nodes (i.e. physical servers) without interrupting production operations, provided you have some spare capacity in your rack and your middleware/applications environments are HA ready, i.e. clustered.
So, it appears that the Exalogic release notes are up for a little revision and we can perform offline vServer migration after all, with a twist!


