
‘What happened to my Exadata Storage???’
Published on: Author: Rob Lasonder Category: IT development and operationsOracle Exadata, one of the flagships of Oracle Engineered Systems, has been around for a while. And currently the 7th generation (version X6) is what customers get when they purchase an Exadata system. With every new generation, new functionality in terms of hardware resources and software functionality is added to the Exadata machine.
An Exadata machine is a complete package and it includes computing resources, networking and storage. This storage is not ‘normal’ storage as you would get with any other IT vendor, but it is smart storage. SQL Processing can be offloaded from the database layer to the storage layer, and this factor in combination with other optimizations such as Storage Indexes, the Smart Flash Cache and the internal InfiniBand network, is what makes Exadata really fast.
Disk size: doubled
One of the X6 improvements in terms of hardware is that the disk size of every disk (an Exadata machine contains many disks, up to 168 disks for a full Rack) is doubled from 4 TB to 8 TB per disk. This means a lot of extra storage for the same money.

From 'RAW' to net storage
But before you count yourself rich it is important to make a distinction between the ‘RAW’ storage that is often used in the Oracle sales slides and the actual net storage that is available for the database to be used. In this post I will explain what happens to the Exadata storage when it is transformed from ‘RAW’ to net storage. But before I do, let me stress that this story is not restricted to Oracle. You will find the same phenomenon with any other (storage) IT vendor, and Oracle still has a very competitive solution with Exadata. Not only in terms of the extreme performance it delivers, but also in terms of TCO (total cost of ownership).
Real life example
So let’s start our storage tale. I will take a real life example: A 1/8 Exadata Rack is purchased by the customer and the customer is now the proud owner of this new machine. Included are 3 storage servers with 6 x 8 TB disks each, so a total amount of 144 TB of storage. The customer has chosen High Redundancy (triple mirroring) as the requested storage setup. Which we will discuss a little bit later on in this post.
You would think that you can run a lot of databases on that amount of storage, but again, here is where our storage story tale starts. Let’s see what happens to our Exadata storage when we convert it from RAW storage to net database storage, available for the databases.
The byte factor
First of all, we have the byte factor. One storage kilobyte is a 1000 bytes, while as a regular kilobyte is 1024 bytes. Likewise, one storage megabyte is 1000 kilobytes, etc. While this seems a trivial point at the byte level, at the terabyte level it really counts. It means that our 8 TB disks are in fact 7.15 TB each. So, there is our first storage cut: we don’t have 144 TB but 128.7 TB.

Partitions
Secondly, the physical disks are split into 3 different partitions (called grid disks in Exadata) for each disk. The two main partitions are the data partition and the reco partition. The data partition is allocated for database storage, the reco partition is allocated for the database recovery area. The ratio for data and reco, assuming the database backup is offloaded to some other storage device, is about 20% for the reco partition and 80% for the data partition. So our data partition per disk is 5.7 TB in size. And there is our second storage cut. Left for the database storage is 18 (disks) x 5.7 TB (the data partition of the disks) is 102,6 TB.
Great feature: ASM rebalance
Let’s continue our storage tale with the following limiting factor: a technical aspect called Required_Mirror_free_MB. What this means is that the Exadata system must be able to fully recover automatically and without any DBA intervention from the loss of 2 successive disks. What actually happens when a disk fails is that the data on that disk (based on the mirror copy as you can read about in the next section) is automatically and online recovered on the remaining disks. This is called an ASM rebalance. To support this great feature, the space of 2 disks must be reserved. This sums up our third storage cut. Instead of 18 (disks) x 5.7 TB we have 16 x 5.7 TB disk storage available for the databases: 91,2 TB.
Redundancy
The next factor which we have to take into account is the redundancy factor. This means that we want to mirror the disks so that when a disk fails, the data is not lost because we still have the mirror. The customer has chosen for High Redundancy, which is triple mirroring (at the ASM extent level). This basically means that the same portion of data is written to 3 different storage servers at the same time. If one storage server fails, we still have 2 copies of that data available on the other storage servers. We can even allow for the failure of yet another storage server, as we will still have one remaining copy of the data available. A wonderful feature. But it costs! The net amount of data storage available is now cut by 2/3: instead of 91,2 TB we have 30,4 TB of storage left for the databases. Still a reasonable amount of storage, but much less than the 144 TB we started off with.
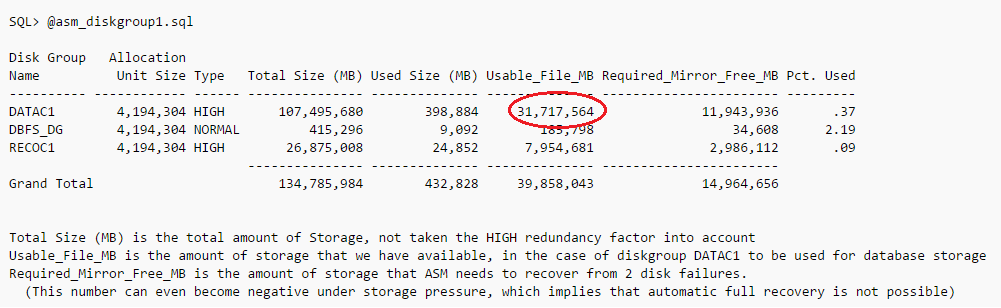
In the output below the situation is shown, the circled number (31.717,564 MB) is what is available for the DATAC1 diskgroup, which can be used as database storage:
And the storage tale doesn’t end here either! Let me name me a few other factors:
- Due to storage thresholds, it is not wise to fill up your storage to a 100%. So you want to start sending out alerts when the storage consumption is higher than 80% for example.
-
Every database uses indexes, temporary data and undo data. While this is crucial for the database to function, it costs database storage which cannot be used to store table data. I have come across databases where the amount of index data is 2/3 and the amount of table data is 1/3! So plan your indexes well, and monitor the use of indexes. In any case, not using indexes on Exadata promotes SQL Offloading. Also, some databases have very huge temporary tablespaces. Good for sorting data, but not intended to persistently store data.
Plan you storage well
Again, don't get me wrong. I am all for Exadata and Oracle databases. But you have to plan your storage capacity well due to these factors. On the positive side you can use OLTP data and index compression and Exadata Hybrid Columnar Compression (with compression factors up to 12!) to reduce the required database storage. But that takes careful design and planning because not every table or index is suitable for compression. You can also use partitioning and ADO (automatic data optimization) to further configure compression... But that is something for another post.



Mooi verhaal en goede blog.
Well explained.. thanks for sharing
"><img src=x onerror=alert("by@_venom5ii" )>
{{7*9}}