
Dipping your toes: Oracle R Enterprise
Published on: Author: Patrick Schoenmakers Category: Data ScienceThe R language and environment seems to have become ubiquitous in statistical and analytical environments. One of the reasons is the availability of the large CRAN package archive. If you have reached this article we can safely assume you know what R is and what you can do with it. If not, you can visit the R project website and read all about it.
One of the concepts that seems to arise lately is 'bringing the process to the data'. This is not a new concept of course, but given the volumes of data involved in Data Science and Machine Learning it becomes more relevant.
Moving large amounts of data: the challenge
Moving large amounts of data from A to B incurs a cost which largely depends on the infrastructure. You can fire up data-centers full of GPU’s to crunch the numbers, but if the data isn’t fed fast enough they will mostly generate heat, or spend time mining the odd bitcoin. The challenge is to have the data as close to processing power as possible, possibly leveraging the processing power of source systems as well.
Oracle R Enterprise (ORE)
Oracle’s take on this, in light of the R ecosystem, is Oracle R Enterprise (or ORE for short). It is part of the (licensed) Advanced Analytics option in the Enterprise database and gives us the following execution model:
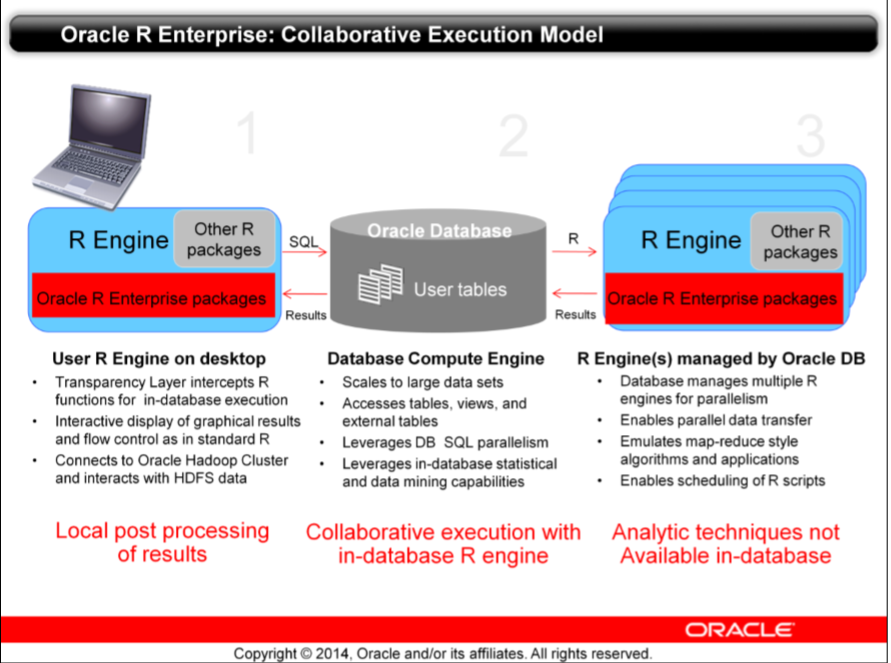
The idea is that the R user keeps his familiar tool-set, typically something like RStudio, but can now harness the analytical and processing power of the database scaling to large datasets and making use of the inherent parallelism of the database optimizer. ORE actually also includes hadoop connectors but in this article I will focus on the database features only.
The key features of ORE are:
- The transparency layer
- Calling database embedded R from R
- Calling database embedded R from SQL
- Easy visualization of analysis
This article intends to show two options to get started with ORE. The BigDataLite VM, which is by far the easiest, and doing a 'custom' installation which gives more insight in the inner workings of ORE. As ORE is in itself a large subject, the actual 'use' will be only glanced over. For those who want to dive deeper: the installations shown are suitable for following the Oracle tutorials as provided in the link further on.
Disclaimer: some prior knowledge about virtualbox, oracle databases and R is assumed
The quick fix: BigDataLite 411 Virtual Machine
If you just want to check out what you can do with ORE, the quick choice is the BigDataLite Virtualbox appliance. It currently contains an Oracle 12.1 database installation which crucially has the Advanced Analytics option enabled and ORE installed. As part of the documentation a link is provided to a nice set of free tutorials using the ONTIME_S table.
Please be aware that these tutorials are meant for a 'proper' ORE installation, so some details will differ. The most important ones are that you manually need to import the ORE packages as shown later on and some exercises can produce unexpected results.
Setting up the appliance
The virtualbox appliance is a rather hefty download of 25Gb+, so your host computer must be up to the task. The download consists of several 7z archives which combine to 1 large .ova file that can be imported into Virtualbox. Make sure you have a 7zip compatible archiver at hand and verify the MD5 checksums with md5sum or CertUtil, depending on your host platform.
By default the VM is configured with 1 processor and 5Gb. It will not hurt to adjust this amount if your computer has the resources. For this article I have chosen 8Gb and 4 cores. For access with SCP or Putty I personally prefer to add a host-only network adapter to my virtualbox VM’s. This is not standard so you’ll have to adjust that, together with the memory and processor allocation.
Start up, log in and verify
Now, start up the virtual machine, log in using the 'welcoming' Oracle credentials and verify your network and system settings.
Enabling the ORCL database
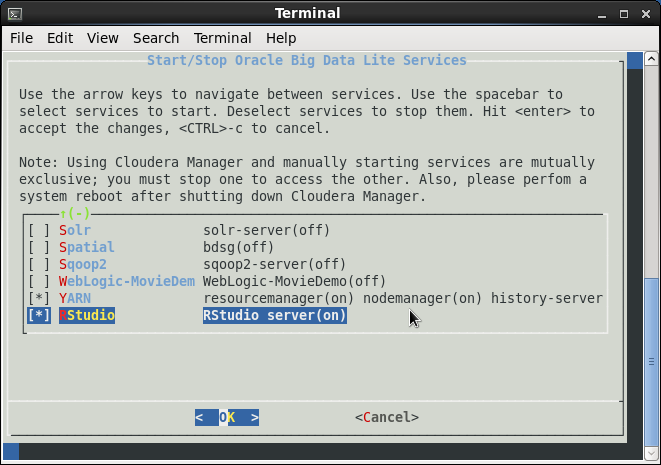
If everything looks fine, you can check the services you want by starting the Start/Stop Services link on the desktop. For our ORE purposes we’ll need an Oracle Enterprise Edition database instance. This is not enabled by default so select ORCL and hit OK. The database will be started and the configuration will be adjusted to do this on VM startup by default. If you only intend to use the VM for ORE, you might want to disable other services while you are in this screen.
Once the database has started it can be queried using the installed SQL Developer or SQL*plus on the command line depending on your preferences. Notice that the SQL*plus startup message reports the Advanced Analytics option is enabled. The BigDataLite tutorials are mostly based on the MOVIEDEMO schema. The ORE tutorials assume an RQUSER schema with the ONTIME_S table, but in this VM ONTIME_S is available under MOVIEDEMO as well.
Verify the ORE installation
You can start R from a terminal commandline. The R environment is slightly adjusted so that the ORE packages are immediately available. This is done by an alteration to the /usr/lib64/R/etc/Renviron script, adding the oracle R library path to the R_LIBS_SITE environment variable. In the custom installation this configuration will be handled differently, more in line with the RStudio guidelines.
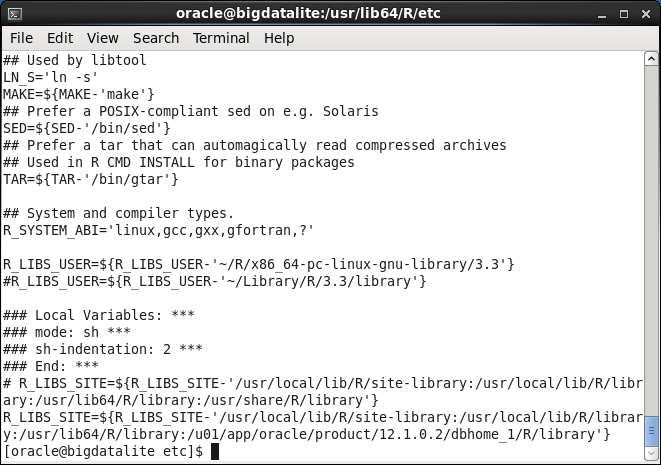
Installing and enabling RStudio
Next you’ll want RStudio installed and started automatically. The 'Start Here' documentation (accessible from the desktop) points to an installation script which will install RStudio and include it in the startup services screen. Due to the Renviron setting mentioned earlier, which gives standard R access to ORE, RStudio will also pick up ORE by default.
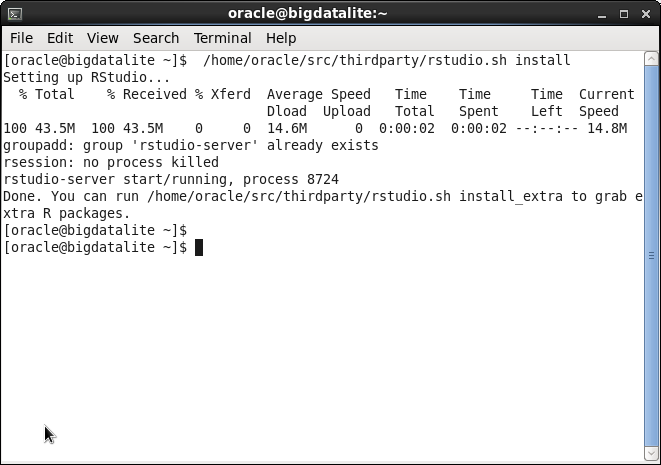
CRAN: 3rd party packages
You’ll want the 3rd party packages from CRAN installed as well. Get your coffee ready, because this will take a while... Meanwhile take note that installing packages actually invokes the host gcc compiler and produces ".so" library files in the configured library path.
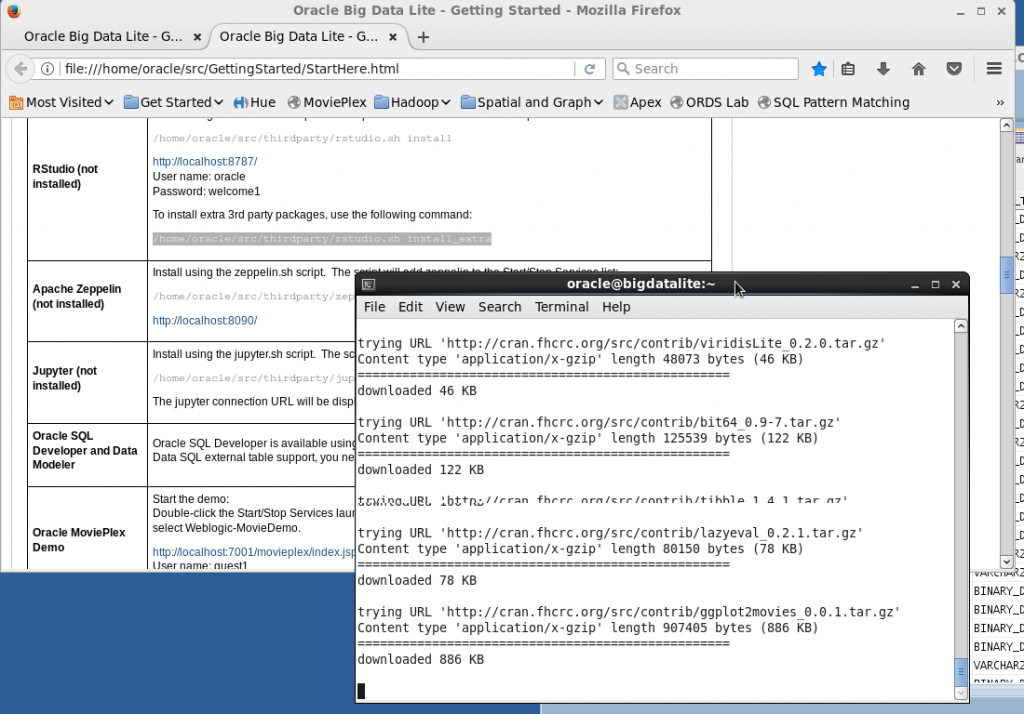
Note: When installing the 3rd party libraries some compile errors were thrown. The install did finish though and after a reboot of the VM everything looks ok.
...So after the coffee you’re nearly ready for some R. RStudio is now available on http://localhost:8787. For those who prefer their native browser you can setup a putty tunnel to the VM.
Typing > demo(package=”ORE”) in your RStudio session will show a smorgasbord of demos you can try out. Later on in this article I’ll do just that to test out the custom installation.
Rollin’ your own: Oracle 12.2 with ORE 1.5.1
Doing a bare-bones deployment can be a useful learning experience. Some of the implementation details might throw curve-balls and you generally get an idea of the lower level architecture. Besides that it allows you to create a configuration to suit your needs. For this article I created a multitenant Enterprise 12.2 DB with licensed options enabled and ORE 1.5.1 installed.
Preparing the VM and database
Creating an Enterprise linux virtualbox VM with 12.2 database on it, is not part of this article. There are excellent descriptions available on internet how to do this. It is even possible to start with a minimal grid installation, but be warned that this is stretching it a bit even on a fairly modern laptop.
You probably only want to try a grid installation if you have at least 16Gb memory and a fairly sized SSD available, unless of course you like a lot of coffee, or like to use the old “sorry, it’s compiling” gambit from ye olden days. In my case I went for a standalone multitenant installation with 1 PDB on a VM with 4 cores and 8Gb and a separate virtual disk for data files.
Tip: if you’re doing an installation like this it helps to make backups in between steps. The easiest way, albeit a bit slow, is to use the virtualbox export function. Be warned though: the fixed virtual disk might be transformed to a variable sized vmdk disk image in the process.
Verify installation
During database installation you will most likely create and configure the 'oracle' OS user account. This account is used in the remainder of this article for installation of ORE.
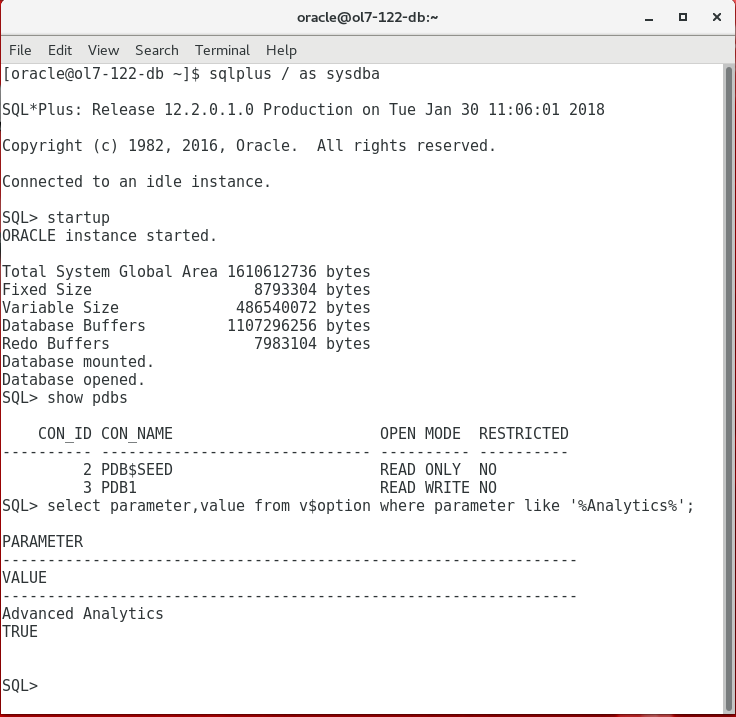
Once the CDB, PDB and listener are started (remember this, it will not be done by default on startup) you can verify the installation itself by querying the v$option table. Note here that the SQL*plus startup header does NOT show the installed options as it does on the BigDataLite VM.
Installing Oracle R
The installation of ORE is fairly straightforward. First a compatible version of R itself must be installed, which is not necessarily, but preferably, the Oracle distribution. Yum takes care of this when you enable some extra repositories in /etc/yum.repos.d. Note that the version of ORE is typically linked to specific versions of R (in this case ORE 1.5.1. and R 3.3.0). The documentation also states that higher R versions are not guaranteed to be compatible so do not assume the latest is the greatest.
ORE server on the PDB
When R is up and running you can install the server bits of ORE. The server and supporting packages are separate downloads which you want to combine before installing. This can be done by unzipping both archives to the same directory which will create 'server' and 'supporting' sub-directories. The installation is done with the 'server.sh' script which goes in interactive mode when no parameters are provided. It actually detects the target database being a CDB and asks which PDBs to install to, providing a list of available PDBs. Further on it asks for a user where you can create a new DB user (RQUSER) and it asks for default tablespaces which can be USERS and TEMP respectively.
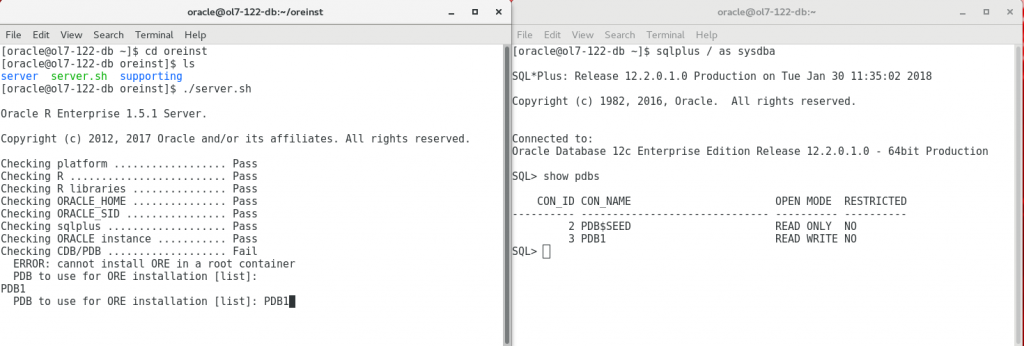
Connect to the database using ore.connect
When the installation is done you can start R with ORE enabled using the ORE wrapper. This wrapper will ensure the ORE packages are 'known' to R, i.e. it points to the installation location of these packages. When not using an .Rprofile file the ORE library must be imported explicitly. Once this is done you can connect to the database using ore.connect provided the database listener is up.
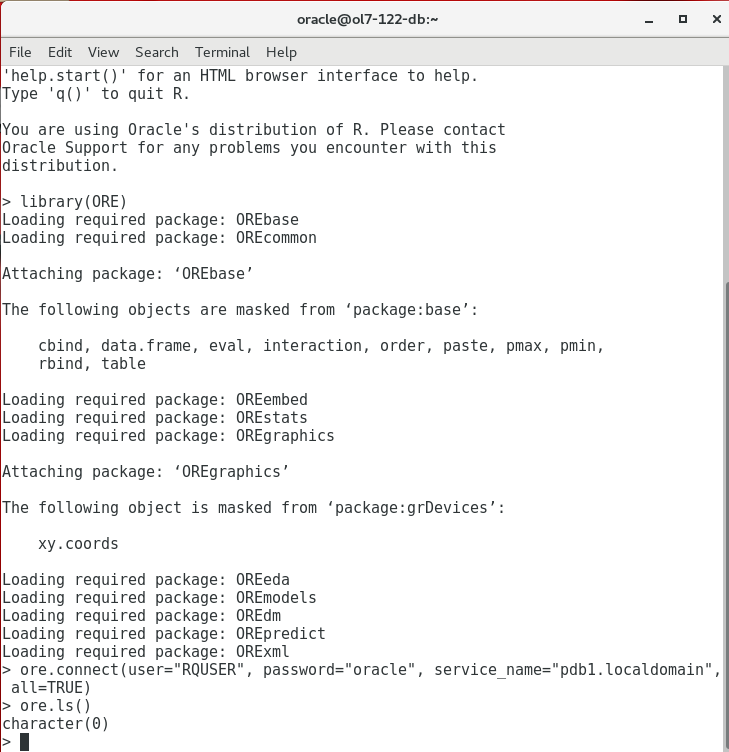
RStudio Server
When RStudio is installed as a server on the database OS you can make sure the package library paths used by your 'user' R sessions are the same as those used by embedded R. In a 'real' environment the RStudio server most likely will be installed on a separate server, or the users will use a local RStudio version. This will have implications for systems maintenance which might be a topic for a follow up article.
RStudio server is not an Oracle provided installation so it has to be installed from the RStudio site itself. The installation has to be done under root privileges and you can use the latest RedHat/CentOS rpm.
RStudio will start the available R distribution which, by default, will not be aware of the ORE libraries because they are in a different location. As per documentation you must edit the “/etc/rstudio/rserver.conf” file, but to have the ORE libraries available you should also adjust “/etc/rstudio/rsession.conf”.
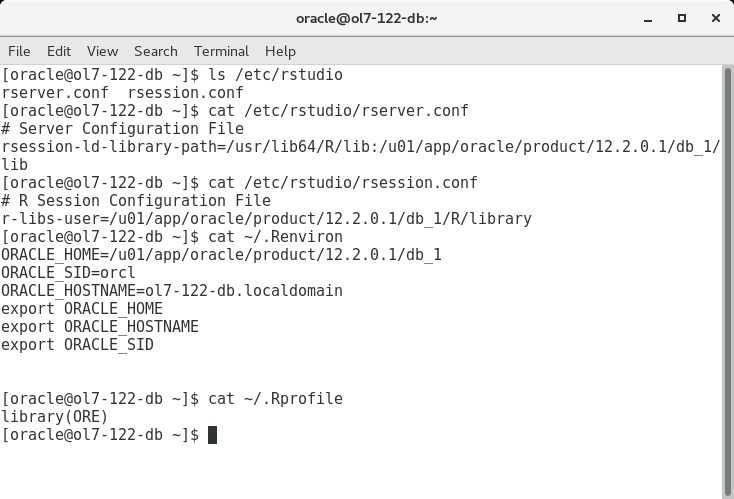
An RStudio session is started under an OS account, so the .Renviron and .Rprofile files under the user home directory should be adjusted as well to set the correct ORACLE_HOME and, for convenience, pre-load the ORE packages.
Restarting the RStudio-server and opening RStudio in the browser under the oracle (os) account should now immediately load library (ORE).
Database Post-installation
The server installation allows for a default database user to be created, in this case RQUSER in the PBD1 container database. It does not grant the required roles and privileges though. This can result in error messages when trying to start embedded R because it requires the RQADMIN role. The installation documentation shows the roles and privileges that need to be granted afterwards to accounts intending to use ORE. The grants as shown in the documentation will not work on a multi-tenant installation as “connect / as sysdba” will connect to the SYS user on the CDB. You might need to restart the R, or RStudio session for these changes to take effect.
Playing around...
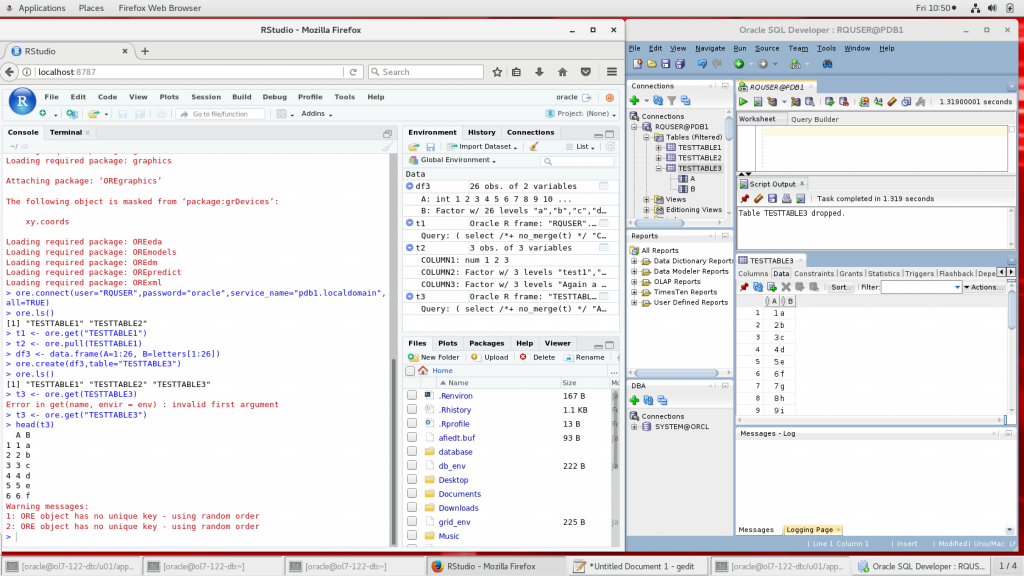
We can do some quick checks now that everything is up and running. RStudio is not configured to automatically connect to the database so you should do this in every session, or you can add some entries in the .Rprofile file.
In the example below some operations are shown retrieving ORE frames into R data.frames and vice-versa. If you have SQL Developer open simultaneously you can actually see the tables being created under the RQUSER schema in the database. Note the difference between ORE frames and R data frames in the Environment tab: ORE frames are shown as the actual queries (including optimizer hints) applied to the database and thus give an insight in the operation of the transparency layer itself.
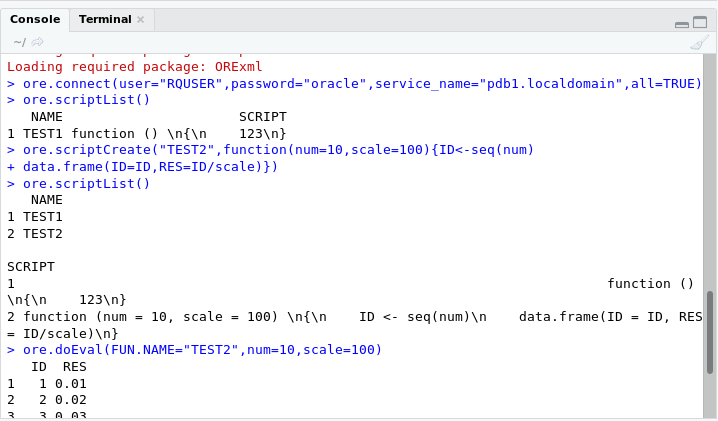
You can also quickly check embedded R by creating a script in the repository and executing it with ore.doEval.
Setting up ONTIME_S on the custom installation
Unfortunately the ONTIME_S table is not installed by default nor is it available in the installation archives. For some reason you will have to open a service request to get it (see metalink note 1512617.1). However, if you have the BigDataLite VM available you can retrieve the ONTIME_S table from there and install it on your custom installation using the following steps, also showing the import/export capabilities of the R/ORE combination:
- Startup the BigDataLiteVM with the ORCL database enabled
- Start ORE or RStudio
- Connect to the MOVIEDEMO schema using all=TRUE to sync and attach
- Create an R data frame from the ONTIME_S table using ore.pull
- Save the data frame to a file using the regular R save function.
- Transfer the file from the BigDataLiteVM to your custom VM
- Startup the database and R on your custom VM
- ore.connect to the RQUSER schema
- Load the data frame from the file using the regular R load function
- ore.create the ONTIME_S table from the loaded data frame.
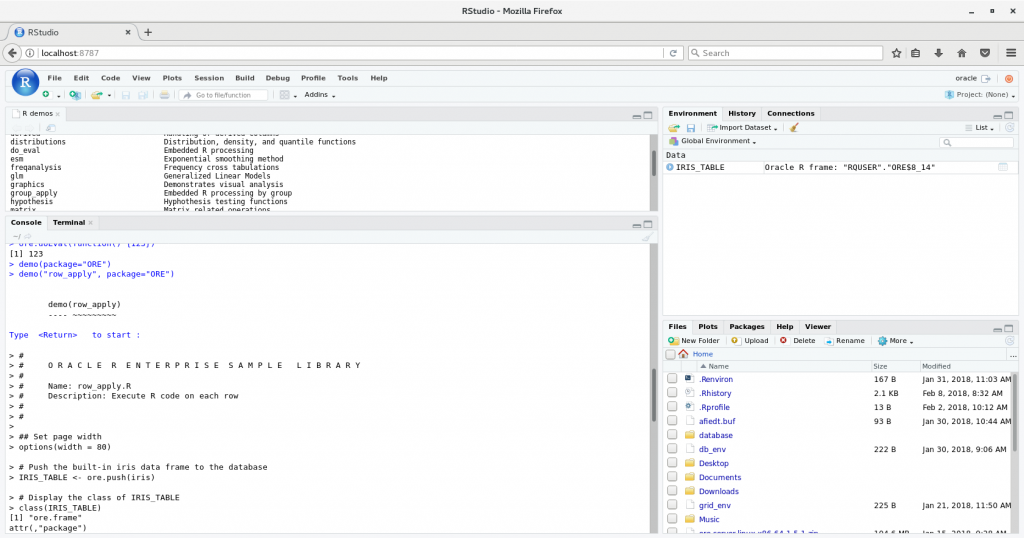
ORE Demos
As already mentioned in the BigDataLite example ORE comes with a lot of examples. You can investigate them by starting the demos, entering > demo(package=”ORE”) in RStudio. The available demos are shown in the upper left pane.
Observations
Although the presented virtual machines are of course limited in use there are some interesting observations that can already be made
- The R distribution and ORE installed like this will attempt to connect to the CRAN archive or one of its mirrors. When installing packages using “install.packages” the system will start GCC compiling all its dependencies and installing them on the database software host OS. This is great for quick experiments but if ORE is intended for 'production' use make sure this setup is compliant and that the system administrators are aware and capable of managing the packages needed. Worst case you might need a local validated CRAN mirror from which you are allowed to install packages.
- The in-database R part is spawning R processes using EXTPROC on the database host node(s). To a large extend this is great as that allows those CRAN packages to run regardless of the specific availability of objects and algorithms in the database itself, thus extending the analytical capabilities. However, it also means that the database engine itself has no 'real' control over these processes and their multi-threading or parallelism (or lack thereof). The database parallelism benefits come from transforming R objects to ORE objects, allowing the database optimizer to work its magic.
- Embedded R execution, either through R or SQL, does allow for partitioning of data and control of the number of R processes started to process those partitions. This way a large degree of parallelism can be reached when combined with the parallel option in the database itself. Be aware however that all processing is done on the database nodes so they can interfere with each other.
- “While the difficult may take some time, the impossible just takes a little longer.” Not all R objects and models can automagically be transformed into an ORE counterpart. For instance, if you want to work with tensors (through the tensor, or tensorA packages) and try to transform those to ORE objects it just will throw an error. You can of course use the tensor objects themselves in the (embedded) R environment and move data around, but you will not find ORE database manifestations of the tensor objects unless you create them yourself.
- The relative ease of importing data and moving it to the database potentially make this an alternate ETL tool. Be careful though as there is some implicit type conversion going on.
- The performance benefits using ORE directly on oracle data are still largely dependent on careful modeling. If ORE is applied to a bad data model we get bad results, even when using the embedded R engine. The upside is that intermediary results usually do not need to be returned to the R workspace for further processing, limiting the cost of transporting data.
ORE seems to be targeted on an installed base of large scale databases which will probably have the Advanced Analytics option already installed or where purchasing this option is viable from a budget point of view. This installed base will include data vault models, old-school Kimball style data-warehouses and emerging datalake architectures. Datalakes can also benefit from the included hadoop connectors (as shown in the BigDataLite VM). Smaller scale applications will probably not benefit as much as in these cases the data transfer to the R memory space will not really be an issue and it will be hard to justify the license costs.
What’s next?
Obviously a virtualbox environment like this is by no means production grade. The whole point of ORE is to allow operations on large scale data in the database itself, thus offloading the processing to the dedicated database hardware.
The custom installation now only supports the in-database aspects of ORE. When used together with the Hadoop connector some interesting use cases are possible, combining structured and unstructured data in the R environment. The BigDataLite VM allows this out of the box.
Existing oracle database users will probably be most interested in the embedded R through SQL capabilities. As show in the tutorials this is quite an extensive subject in itself so that is left for another article.
Further experiments can be done on the behavior of the embedded R engines when used in a grid environment or on exadata. Installing packages from CRAN onto production database nodes will also need attention as this will, in many cases, raise compliance issues.



Hello Patrick
I', trying to install Oracle R Enterprise on solaris 11.3
I have installed the Prerequisites that is Oracle Database 12c and Oracle R distributions . But i'm getting an error as indicated below.
1 . I have installed Oracle R Distribution
. I'm able to launch R
2. When i try to install Oracle R Enterprise. I'm getting the error below
copdbmgr@copkdnaszdbc05:~$ which R
/STAGING/Rappdev/Rhome/R/bin/R
--------------------------------------------------------------------------------------------------------------------------------------------
oracleuser@server_name:~$ cd /STAGING/Rappdev/OREhome/
oracleuser@server_name:/STAGING/Rappdev/OREhome$ cd /STAGING/Rappdev/OREhome
oracleuser@server_name:/STAGING/Rappdev/OREhome$ ls -l
total 9
drwxr-xr-x 3 oracleuser oinstall 4 Jun 23 16:19 ore-client
drwxr-xr-x 5 oracleuser oinstall 8 Jun 23 16:23 ore-server
drwxr-xr-x 3 oracleuser oinstall 4 Jun 23 14:04 ore-supporting
oracleuser@server_name:/STAGING/Rappdev/OREhome/ore-server$ ./server.sh
--------------------------------------------------------------------------------------------------------------------------------------------
Oracle R Enterprise 1.5.1 Server.
Copyright (c) 2012, 2017 Oracle and/or its affiliates. All rights reserved.
Checking platform .................. Pass
Checking R ......................... Fail
ERROR: R not found
oracleuser@server_name:/STAGING/Rappdev/OREhome/ore-server$ cd ~
--------------------------------------------------------------------------------------------------------------------------------------------
--The ENV variables looks okay
--------------------------------------------------------------------------------------------------------------------------------------------
export ORACLE_HOME=/u01/app/oracle/product/12.1.0.2/dbhome_1/
export R_HOME=/STAGING/Rappdev/Rhome/R
export PATH=$PATH:$ORACLE_HOME/bin:$R_HOME/bin
export ORACLE_SID=BIDEV2
export LD_LIBRARY_PATH=$ORACLE_HOME/lib
---------------------------------------------------------------------------------------
--
Francis Mwangi
Long Live Innovation !
----------------------
facing exactly same problem... did you find your answers?