
Explore Apache Cassandra
Published on: Author: Rodrigo Agundez Category: Data ScienceInitially developed at Facebook for inbox search, Apache Cassandra is an open source, distributed and decentralized storage system. It is a type of NoSQL database written in Java highly scalable and high performance database design, to handle large amounts of data across many servers with no single point of failure.
- Elastic scalability
Allows to add more hardware to accommodate more customers and more data easily. - No single point of failure
- Linearly Scalable
Increases throughput proportionally to increment of number of nodes. - All data formats
Accommodates structures, semi-structured and unstructured data. - Easy data distribution
- No single entry point
Queries can be executed from any node. - Fast writes
It performs blazingly fast writes and can store hundreds of terabytes of data.
PERFORMANCE: LET’S TAKE A LOOK
Linear Scaling…
One of Cassandra’s hallmarks is its high performance, for both reads and writes, which scales linearly when new nodes are added to a cluster. In the image it is shown the client writes per second in the y-axis vs the number of nodes in the cluster in the x-axis.
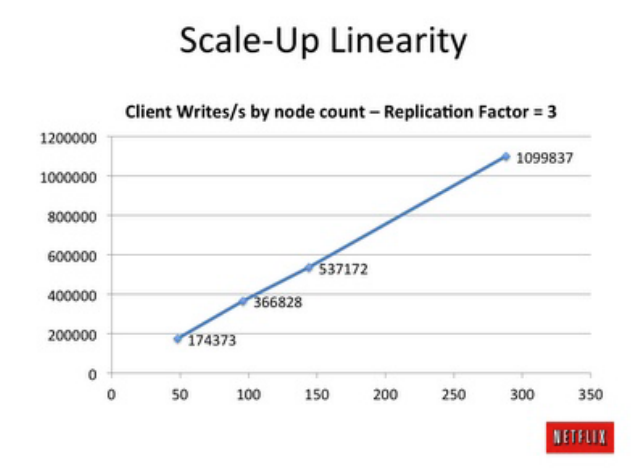
A complete study can be find here
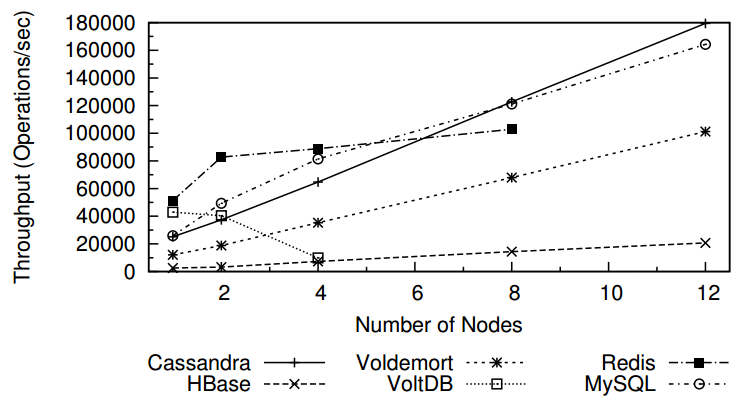
… vs OTHERS – Linear Scaling …
Cassandra achieves the highest throughput for the maximum number of nodes in all experiments with linearly increasing throughput from 1 to 12 nodes.
… vs Hbase (NoSQL database)
- 10x more read throughout
- 8x faster read latency (up to 100x faster)
- 8x faster read latency (up to 100x faster)
- 8x more write throughput
- 8x faster scan latency
- 4x more scan throughput
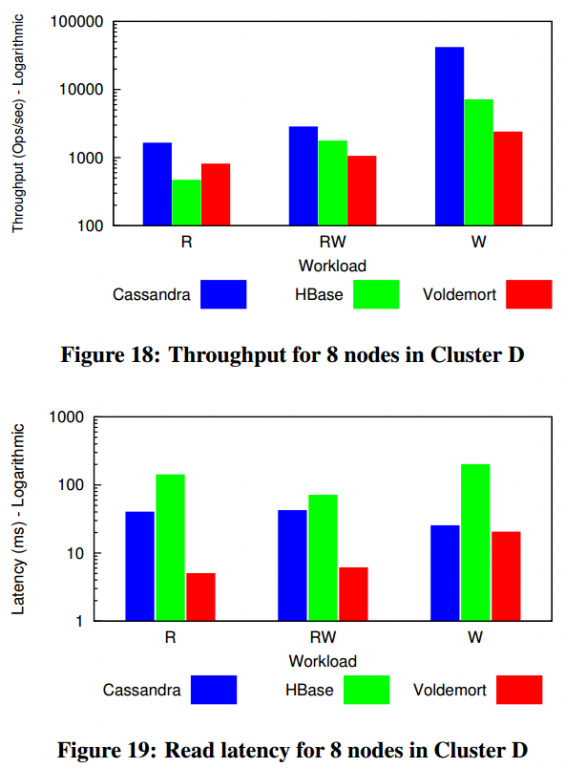
High performance at extreme scale
The bottom line of this comparison: Cassandra, when put to the test, offers high performance at extreme scale, which cannot be said of any other NoSQL database.
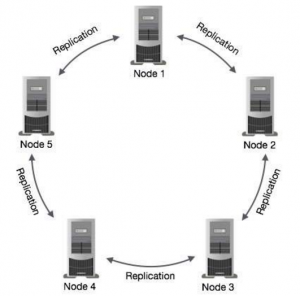
Architecture
One or more of the nodes in a cluster act as replicas for a given piece of data. If it is detected that some of the nodes responded with an out-of-date value, Cassandra will return the most recent value to the client. Cassandra uses data replication among the nodes in a cluster to ensure no single point of failure.
Data Model
Keyspace (like database in SQL)
This is the outermost container for data. Each keyspace has defined:
- Replication factor: Number of clusters with copies.
- Replica placement strategy: how to place replicas.
Column Family (a sort of table in SQL terms)
This is a container of an ordered collection of “fluid” rows. Columns are not defined, each row can containe different columns and columns can be freely add at any time.
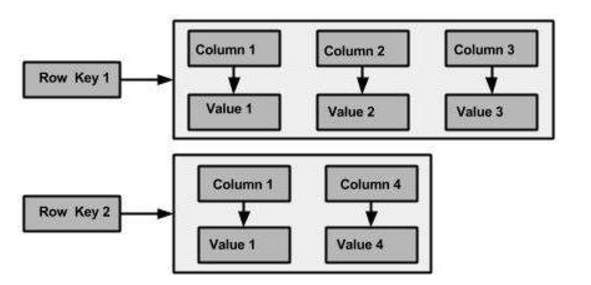
Column
Basic data structure of Cassandra. Contains key or column name, value and a time stamp.
Extra Notes:
The data model can be viewed as a database (Keyspace) where tables (column families) are lists of nested key-value pairs (Row x Column Key x Column value).
Because NoSQL databases like Cassandra do not support operations like SQL joins, data tends to be highly denormalized. While such a thing (wide rows) is normally a problem for an RDBMS, Cassandra provides exceptional performance for objects with many thousands of columns.
On a single node, NoSQL offers absolutely no advantages over RDBMS.
Query Language
In Cassandra, objects are created, data is inserted and manipulated, and information queried via CQL – the Cassandra Query Language, which looks nearly identical to SQL. Developers coming from the relational world will be right at home with CQL and will use standard commands (e.g., INSERT, SELECT) to interact with objects and data stored in Cassandra. Down here a snapshot of Cassandra in my laptop.
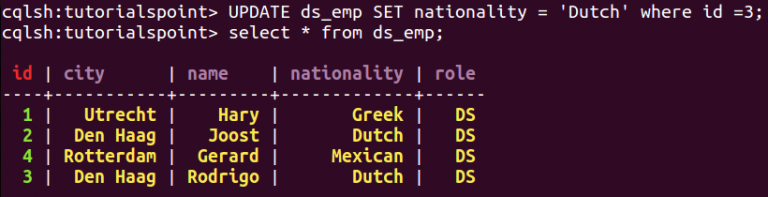
It’s very easy to create a Keyspace (database) and assign the desired Cassandra architecture. Once created, Cassandra will take care of the distribution and maintenance of the system:
Used Cases
They offer personalized recommendations, an advanced cart abandonment recovery system, an in-site behavioral targeting solution and a set of gamification features.
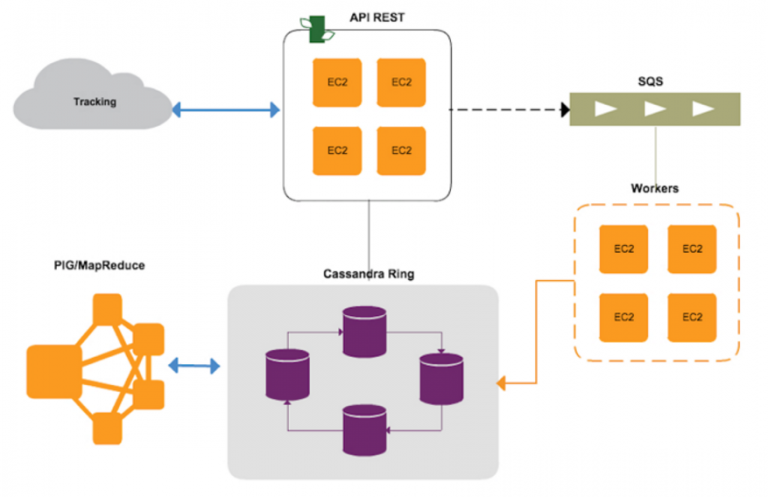
To provide full personalization to our customers, we need to track every possible action the users perform in the online stores. We are currently using Cassandra v1.2.15 in a cluster built in Amazon EC2 Amazon-Linux machines. Cassandra gives support to the our whole NoSQL infrastructure from the bottom of it. Currently, the cluster goes from 2 machines minimum up to a finite number regarding the traffic. It is very flexible, thus it allows us to boot up new machines and join them into the ring in less than two minutes.
In 2010, Netflix began moving its data to Amazon Web Services (AWS) to offer subscribers more flexibility across devices. At the time, Netflix was using Oracle as the back-end database and was approaching limits on traffic and capacity with the ballooning workloads managed in the cloud.
The Netflix team performed an extensive evaluation of their database options and Apache Cassandra™ was the clear winner. Besides affordable scalability, Cassandra’s schemaless architecture ensures no single point of failure and eliminates any downtime incurred by schema changes.
The entire migration of more than 80 clusters and 2500+ nodes was completed with only two engineers. The system drives throughput to more than 10 million transactions per second. On average, Netflix processes more than 2.1 billion reads and 4.3 billion writes per day. Cassandra’s multi-data center replication enables Netflix to get more flexibility than ever to create and manage data clusters.
Read also my blog about Apache HBase.


