
Predict the future with data
Published on: Author: Gerard Simons Category: Data ScienceCan you predict the future with data? Google Prediction API, as the name suggests, allows you to create predictive models from your data. (How) does it work? Read my experience with the API.
The Google Prediction API is an integral part of the Google Cloud Platform. Similar to the relation of Amazon Machine Learning to Amazon Web Services. The API hides much of the complexity of choosing the right model, the right parameters and the training and classification methods. On the downside, the process is not very transparent.
Dataset: a fair comparison
To get a fair comparison with Amazon Machine Learning, we use the same dataset as used there. The description of the datasets is copied from our previous blog on Amazon Machine Learning.
‘Initially, we needed a dataset for experimental reasons with a relatively big size but which was kind of straightforward. Open datasets are available on numerous repositories, so looking around in the UCI machine learning repository, we ended up with the Bank Marketing dataset that seemed to fit our needs.’
This dataset is related to the direct marketing campaigns of a Portuguese banking institution. The story behind it is that one or more phone contacts were made to the client in order to predict if the client would or would not buy the product. There are 45.211 entries with 20 input variables (numeric and categorical) such as age, job, marital status etc and the output variable is binary.
More details for this dataset can be found here.
Let’s go: upload & create
A first step is uploading your data and creating the datasets. CSVs can be uploaded to Google Cloud Storage (Similar to S3 in Amazon Web Services), from which datasets can be created. The image below shows our cloud storage page within the developers console from which we created a bucket and uploaded the CSV files.
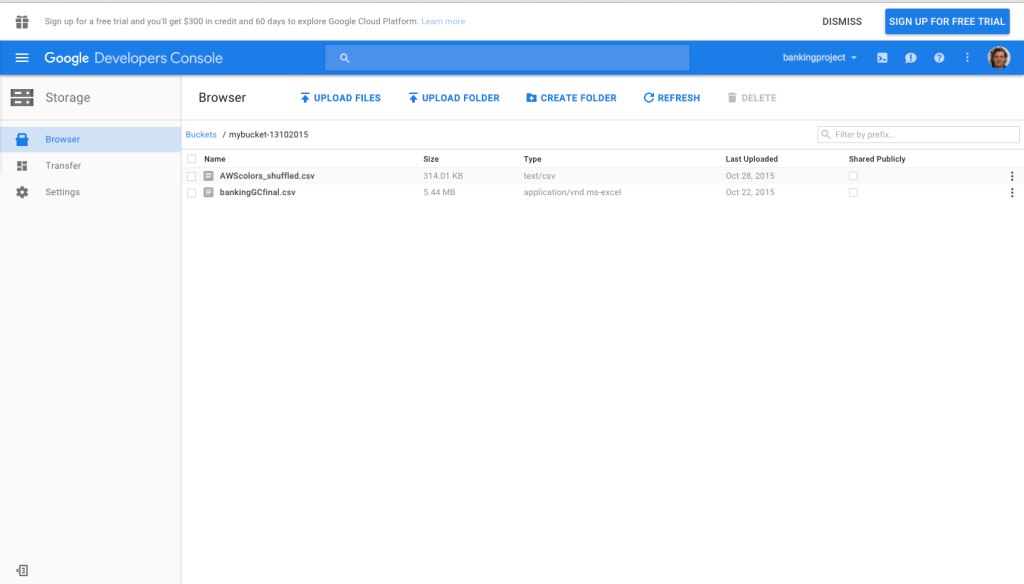
A few important points to note here are:
- Make sure the first column is the target label (i.e. the attribute you want to predict)
- Make sure to put quotations mark around every text feature
- Do not include a header row in your CSV file
- Make sure to use commas as column separators (no semicolons, tabs or other)
Modeling
Immediately apparent from the Google Prediction API is that it does not have a nice web interface such as Amazon Web Services, it is simply a RESTful API, that works with HTTP requests and returns JSON responses. Fortunately, you can use the Google API Explorer, which provides a simple web interface wrapper for most of Google’s APIs.
A RESTful API of course makes it possible to call the API from virtually any programming language, but could require significant effort to implement. Fortunately there are two well documented ways of communicating with the Prediction API.
Two common ways of doing it are:
- Write the code in Python so that you call the appropriate API each time.
- Call and run each API separately from the Google API explorer.
We started using Python, as we are already familiar with it. Unfortunately, we did not find using the OAuth client to authorize our requests was completely obvious. Nevertheless, with enough effort it should be possible, and if you intend to use Google Prediction API in a production settings, this could very well be the way to go. You can find further instructions on doing so here.
For our example however, using the Google Prediction API in the Explorer, was a much easier to do some experimenting with. A nice feature is that it has integrated OAuth2 authentication.
Below are the available prediction APIs in the Google API explorer:
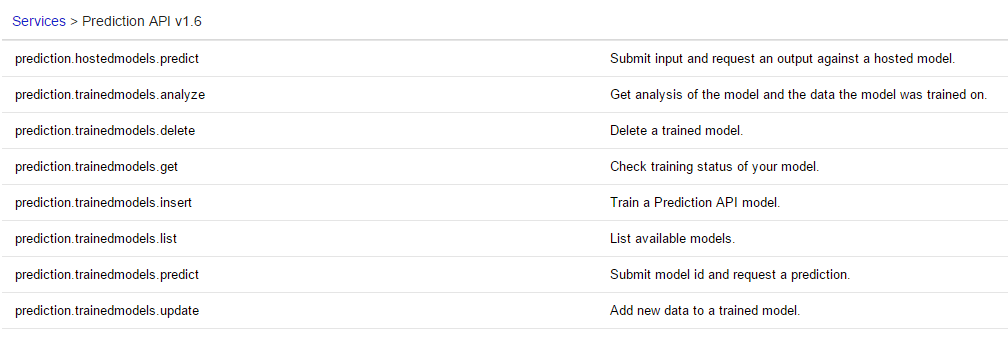
In order to train our models (whatever models they may use) we used the prediction.trainedmodels.insert API as follows:
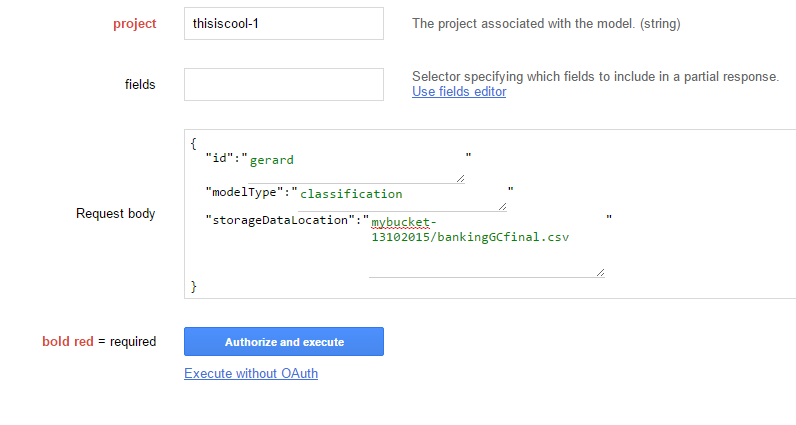
where the id corresponds to a unique id for this request, the modelType is either classification or regression and the storageDataLocation is the path in the Cloud Storage bucket we have used to store our dataset.
The training and the evaluation of the models did not last long; it took less than 5 minutes.
Results
The accuracy of the classification is 91% as can be seen from the response below:
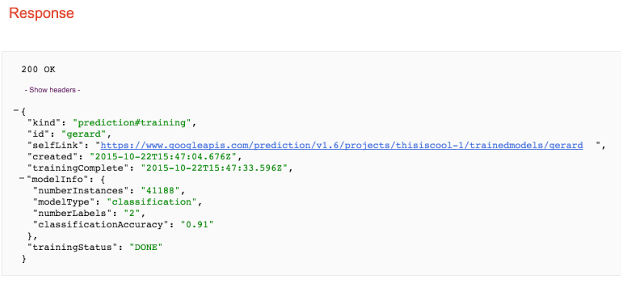
Google prediction API also has a analyze function that is able to returns statistical descriptions of the data, such as the number of data points per data attribute, the mean and variance of its distribution. It also returns the confusion matrix of the model.
Evaluation
The main remark is the way Google predicts the outcome. It is a black box with no knowledge which models are used and under what conditions. This is not necessarily bad, as long as you believe them when they say that they use the state-of-the-art models and tune them adequately enough.
The preparation of the dataset was time consuming. Adding commas, putting quotation marks for text features, making the first column the target outcome and leaving out header rows are not difficult to apply, but need some time.
The interface was not very friendly to the user. Although we managed to find sufficient documentation, we needed to navigate from one page to the other. There was not a constant flow in the information we were exposed to.
When we got the results for the test set, only accuracy was displayed. We had to run another API, namely the trainedmodels.analyze. It is important to note however that this data is much less directly usable than the way Amazon Machine learning reports these statistics. In Amazon, we can see distribution graphs, histograms and other visualisation directly in the browser, but here they are returned only as part of the JSON response, so as raw values. To make sense of these, you have to convert it to something that is more easily understood.
Overall, the performance was as expected (similar to Amazon), but we needed to get acquainted with the interface first. Also the time needed for training and evaluation of the models was less than 5 minutes, which seems very quick, depending on the extent of models and parameters tried.
The monetary charges were also fine: We were charged with approximately 10$, while predicting the outcome of two datasets, while we run each one several times. The banking dataset is considered big in terms of scientific purposes. It is however not completely clear how much a problem would cost you beforehand, but this seems to be the usual problem with these pay-as-you-go methods.


