
Patching Oracle Exalogic - Updating Linux on the compute - Part 2
Gepubliceerd: Auteur: Jos Nijhoff Categorie: OraclePatching Exalogic part 4b
In the previous post we started on patching the Exalogic compute servers, and we applied the patch procedure to one of them (node 8), taking patchset 2.0.0.0.1 as an example.
The idea is to demonstrate that patching of the compute nodes can be done in a rolling fashion, maintaining application availability during the upgrade, provided that your application is deployed in redundant (HA) fashion, for example in a Weblogic cluster spread over more that one physical node. There can be four (1/8th rack) to 30 (full rack) compute nodes in an Exalogic rack.
In this post we will check if all went OK, finish the patching procedure for node 8 and complete the rolling upgrade procedure for all our other Exalogic compute nodes. This will also be the last post in our Exalogic patching series for physical setups, as we have shifted to a virtualized stack.
Let’s log back into our already updated node 8 and see if all went well. First we check the logfile /opt/baseimage_patch/scripts/ebi_20001.log. No obvious problems there, OK.
Now check the status of our Infiniband connections:
Our infinband interfaces are running fine. Now we check the new version of our compute node base image:
Looking good, let’s check our update history as well:
Nice, you can see all the updates we did from the day our Exalogic was rolled into the datacenter… Check the kernel version:
Compare this to an as yet unpatched 2.0.0.0.0 node :
Good, it looks like all went well for node 8.
Post Patching
There is also some post patching work to do: we need to make some changes in the BIOS. In particular, enabling SR-IOV is of note, as this will prepare us for introducing virtualization to the Exalogic stack later on.
A few BIOS parameters need to be reconfigured following application of the patch. The following are the required changes:
- Intel(R) C-STATE tech must be enabled for the CPU
- Maximum Payload Size for PCI Express needs to be changed to 256 Bytes
- SR-IOV Support should be enabled
We need to logon to the Lights Out Manager of node 8 so we can make the server boot into BIOS and make the changes.
As we have started a console session from the ILOM we see the server boot into BIOS and we can then go through the BIOS menus and make the required changes as demonstrated in the screenshots below:
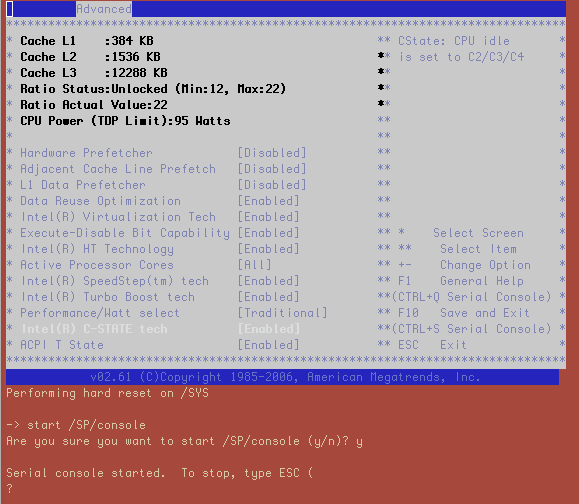
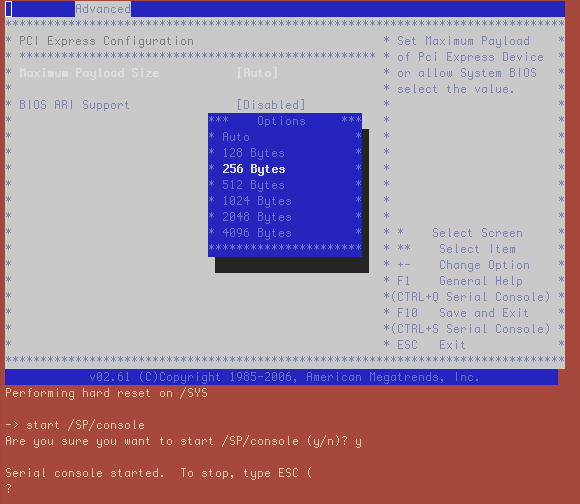
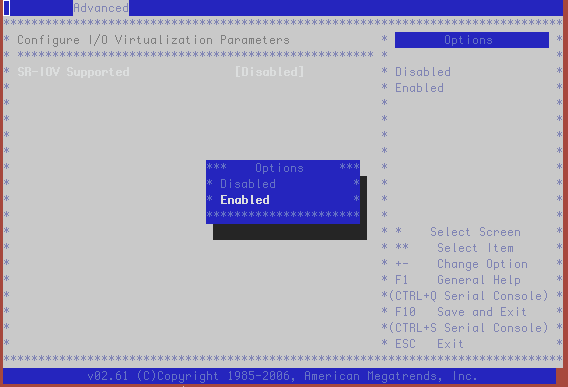
This wraps up our patch procedure for our first node. Now we can look at the other seven nodes in our quarter rack system.
Rolling upgrade of application cluster nodes
After some days to test the waters and assure there are no unexpected issues with node 8 after upgrading it, we decide to go ahead and finish the upgrade.
We decide to do a rolling upgrade on our Weblogic HA cluster which is running on nodes 1 and 2 and also on a Business Process Management HA deployment on nodes 3 and 4. So I had to upgrade nodes 2 and 4 in parallel, leaving the aforementioned applications running on nodes 1 and 3. When upgraded succesfully, we could then do a failover of the applications and upgrade nodes 1 and 3 in turn, assuring continued availability of these critical applications during the whole upgrade process.
Patching multiple nodes at the same time can be achieved by using the setup_dcli.sh and run_dcli.sh scripts. Quoting from the patch documentation :
We run the patching from our newly upgraded node 8. First we check that password-less login has been configured for all nodes. If not, now is the time to set this up (described in the README). We check for password-less login by using the dcli command. As an example we check the baseimage and build version on all nodes.
[root@xxxxexacn08 josn]# <strong>dcli -t -g allnodes-priv.lst cat /usr/lib/init-exalogic-node/.image_id | grep exalogic_version
</strong>xxxxexacn01-priv: exalogic_version='2.0.0.0.0'
xxxxexacn02-priv: exalogic_version='2.0.0.0.0'
xxxxexacn03-priv: exalogic_version='2.0.0.0.0'
xxxxexacn04-priv: exalogic_version='2.0.0.0.0'
xxxxexacn05-priv: exalogic_version='2.0.0.0.0'
xxxxexacn06-priv: exalogic_version='2.0.0.0.0'
xxxxexacn07-priv: exalogic_version='2.0.0.0.0'
xxxxexacn08-priv: exalogic_version='2.0.0.0.1'
If password-less login had not been setup the dcli tool would have asked for the passwords of nodes 1-7. If you have already set this up before (as we have here), this step can be skipped. However, for demonstrational purposes we will execute the pasword-less setup anyway:
Compute node 8 has been striked out as it does not need to setup equivalency with itself.
[root@xxxxexacn08 scripts]# <strong>dcli -t -g machine_list -k -s "\-o StrictHostKeyChecking=no"
</strong>Target nodes: ['xxxxexacn02-priv’, 'xxxxexacn03-priv’, 'xxxxexacn04-priv’,
'xxxxexacn05-priv’, 'xxxxexacn06-priv’, 'xxxxexacn07-priv’]
root@xxxxexacn01-priv’s password:
root@xxxxexacn03-priv’s password:
root@xxxxexacn04-priv’s password:
root@xxxxexacn06-priv’s password:
root@xxxxexacn05-priv’s password:
root@xxxxexacn07-priv’s password:
root@xxxxexacn02-priv’s password:
xxxxexacn01-priv:ssh key added
xxxxexacn02-priv:ssh key added
xxxxexacn03-priv:ssh key added
xxxxexacn04-priv:ssh key added
xxxxexacn05-priv:ssh key added
xxxxexacn06-priv:ssh key added
xxxxexacn07-priv:ssh key added
Next we have to configure some properties in the USER section of the dcli.properties file. Change the values of the following to suit your environment: PATCH_DOWNLOAD_LOCATION and LOCAL_BASE_IMAGE_LOC.
No need to cleanup the LOCAL_BASE_IMAGE_LOC directories on the nodes in question from any previous activities before starting your patch run, as the setup script will do this for you. Now strike out the nodes in our machine_list file that we don’t want to patch (yet), leaving nodes 2 and 4 to be patched:
The next step is to run the setup_dcli.sh script:
This will copy the necessary files to the local directories /opt/baseimage_patch on nodes 2 and 4. If the script reports issues, investigate and fix them.
Application failover
If not done already, now is the time to shutdown the application processes on nodes 2 and 4, so the user sessions will failover to nodes 1 and 3 and we are free to run the upgrade. Check if there are no leftover application user processes that could hamper unmounting of filesystems and rebooting.
Executing the parallel patching process
Before setting the actual upgrade process in motion, ensure that all Enterprise Manager agents are stopped and NFS mounted file systems are unmounted on all nodes being patched in parallel. The patch script will try to unmount NFS shares and will exit if any unmount command fails. In addition, to save some downtime, consider to temporarely “hash out” the NFS mountpoints in /etc/fstab (but to be safe, do not remove the /u01/common/patches mountpoint!)
Now setup a console sessions to each node via the ILOM, so you can see all that goes on once patching has started. This example is for node 2:
Finally, we can kick off the parallel upgrade process for nodes 2 and 4 with the run _dcli.sh script:
This will execute the patch process on the two nodes, analogous to what we have done before on node 8, but now in parallel. Monitor the patching process via the two console session we opened via the ILOMs. The nodes will be rebooted multiple times. Finally, perform the BIOS changes (“Post Patching steps”) for both nodes using the two ILOM session already opened to watch the proceedings.
After doing this, check the patch logfile and image versions on nodes 2 and 4 and restart the agents if they are not configured to startup automatically (which could slow down patching, hence I turned it off beforehand). The .scl scripts are simple scripts to perform the desired actions.
Now that our nodes 2 and 4 have been upgraded succesfully, we can restart the application processes on these nodes. Then we can do our application failovers to them, and repeat the same patching procedure for nodes 1 and 3. Thus, we have patched all four compute nodes while maintaing application availablity. The other nodes 5, 6 and 7 can be upgraded similarly by modifying the machine_list file, depending if they may be patched in one go or not.
CONCLUSION
This concludes my series on the patching procedures for physical Exalogic configurations. We started with the Infiniband switches, then we did the ZFS 7320 storage and finished with the X4170-M2 compute servers. Throughout the upgrades, I have demonstrated that they can each be executed in a rolling fashion, provided you have setup high availability for your applications.
Publicatiedatum: 19 maart 2013


