
My experience with Google Big Query
Gepubliceerd: Auteur: Charalampos Sarantopoulos Categorie: Java & WebWhat is my experience with the Google Big Query platform for performing time consuming and complicated operations? Discover it in my blog! Let me share with you the procedure I followed to perform a big query on Google cloud.

In order to access the Google cloud Big Query, a Google account is required. I used the same account as the one used for Google prediction API . So, the only thing I had to do is to create a new bucket in an existing project, where I had to upload my data to be queried.
My dataset
The database I will use contains information about twitter users. This database was created in order to predict the gender of the twitter user based on different features of a twitter account (name, picture, tweets, theme etc.) It contains several tables but I’m only interested in two; the t_tus_twitteruser and thet_tjs_twitteruser_json. The t_tus_twitteruser among others contains the id of the user, the screenname, the prediction based on the name, the confidence of the prediction and so on. The t_tjs_twitteruser_jsoncontains the id of the twitter user and a json file with all the attributes of this user, as fetched by the Twitter API.
From each of the two tables, I created a subset to use for querying purposes. I did that because the data were initially stored in a MySQL database and was not easy to create dump files of such a size.
The subset for the t_tus_twitteruser table is parsed by using the following query:
The subset for the t_tjs_twitteruser_json table is parsed by using the following query:
These two subsets are also going to be uploaded in the Google cloud for making comparisons between the two environments. I managed to upload the subset of the json table in the Google cloud, but for different (technical) reasons it is split in 3 pieces/tables, namely t_tjs_twitteruser_json_2, t_tjs_twitteruser_json_3, t_tjs_twitteruser_json_4. An important note is that due to some malformed strings in the Twitter JSON some 20.000 (-2%) of the records were skipped when uploaded to Google Cloud. These errors are most likely due to invalid characters in some parts of the user’s profile data. They are very hard to find and fix, and I did not think the impact of these bad records would be very big.
Creating a ‘BIG’ query
The queries to be used should be applicable to both MySQL and Google Big Query platform. The first task was to find a query that needs a considerable amount of time to finish when applied to the MySQL database. Such a query should contain lots of data combined with time consuming operations, like regular expressions. I also found it interesting if I could run some other queries of different nature for instance queries with group by clauses or queries that contain joining tables.
The query in general should be expensive enough so that I can observe the difference, but not too expensive so that I do not need to wait for a long time. Also, I wanted the actual ‘querying’ to take up most of the total running time, rather than the fetching, as the fetching would be more dependent on the internet connection rather than on the speed of the execution at the server side.
Therefore, I came up with three different types of queries:
1) RegExp
Regular expressions are a powerful way of finding strings matching a certain expression. In my test case I wanted to find email addresses ending with a .com domain in the JSON data of the Twitter users.
2) Group By
Grouping operations are notorious for requiring a lot of computation, so I was interested in finding differences in computational time in Google Big Query vs MySQL. I designed a simple query that groups by the tus_picture_prediction (what the profile image recognition thought the sex was) and thetus_name_prediction (what the name predictor thought the sex was). It also shows the count, so that you can easily see for how many cases the classifications agreed and disagreed. It also orders by count.
3) Join
Joining tables is also considered as an expensive query. In my case, I joined the tables t_tus_twitteruser and t_tjs_twitteruser_json.
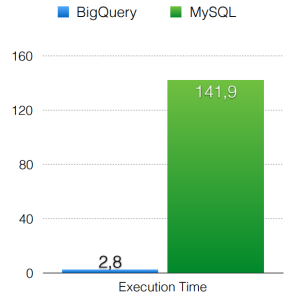
RegExp
MySQL
Time(sec): 141.9
Google BigQuery
select count(*) from ungp.t_tjs_twitteruser_json_2, ungp.t_tjs_twitteruser_json_3, ungp.t_tjs_twitteruser_json_4 where regexp_match(tjs_json,r'[a-zA-Z0-9._]+@[a-zA-Z0-9._]+.com')
Time(sec): 2.8
GroupBy
MySQL
Time(sec): 9.6
Google BigQuery
Time(sec): 9.6
Google BigQuery
Time(sec): 3.3
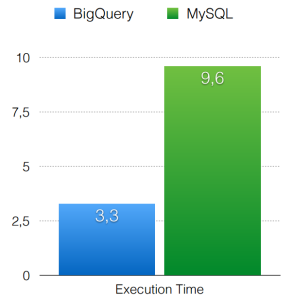
Join
MySQL
Time(sec): 9.6
Google BigQuery
Time(sec): 3.3
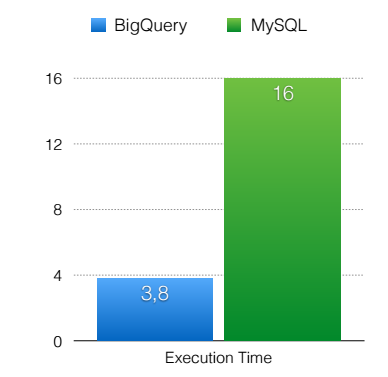
Join
MySQL
Time(sec): 16
Google BigQuery
Time(sec): 3.8
Comparison
Firstly, the difference in time between the two platforms is obvious. For RegExp, the difference is chaotic 141.9 – 2.8 = 139.1 seconds. Using the group by clause, the difference is 9.6 – 3.3 = 6.3 sec. Finally, when joining tables, the difference is 16 – 3.8 = 12.2 seconds.
The biggest difference occurs with RegExp, but in general, it will make much more sense and the difference in time will really matter when I deal with massive amount of data.
GroupBy
Join
RegExp
Evaluation
The first challenge was to upload the dataset into the Google cloud. I needed to have a big dataset and specifically two tables so that I can run some join queries. The extraction of the tables from MySQL was not easy, since fetching the first 10.000.000 results most of the times ended by crashing the client. After some tries, I split one big table into 3 subtables to upload each one separately.
The extracted table should be stored as a CSV and uploaded into a bucket. A CSV of that size is not easy to edit and a slight change that influences the whole document might take some time.
Errors
The platform of Big Query, once I have stored the datasets in the bucket, has the option to create a new table based on the stored CSV files. Through different steps, one should define the name of the table, where it is stored, its schema and some other parameters, like leaving the head row out etc. It was this process that costed us the most time, as many errors in the CSV files were encountered and were hard to fix. It would require editing the CSV file and re-uploading it again, making it a very slow and tiresome process. One of the problems for instance was the ‘NULL’ values that I had to leave out. Another one was the required quotations around string values. Using some UNIX trickery such as the ‘sed command’ I finally managed to format these files.
In order to get a wider picture, the procedure so far was not very user-friendly. One should preprocess the document (best case scenario to know beforehand what is needed) in order to be able to start executing some queries.
The big query part is another story. Its SQL-like language makes it easy to create the queries but the syntax is not always the same with the one used in MySQL client. See for example the differences in the queries for the join and the RegExp-types.
The whole procedure
All in all, the whole procedure, from trying to come up with my own dataset to bring it to the format needed for the Big Query, took me more time than expected. On the other hand, someone who has already some experience with that, might find Big Query handy. The gains of using Big Query might become worthwhile when one has to deal with massive amount of the data. Still the problem of getting the data into Big Query is a non-trivial one. If a more usable data transfer from SQL databases to Big Query was available (without the intermediate step of creating CSV files), the process would probably be much more efficient.


